Transformers的背景
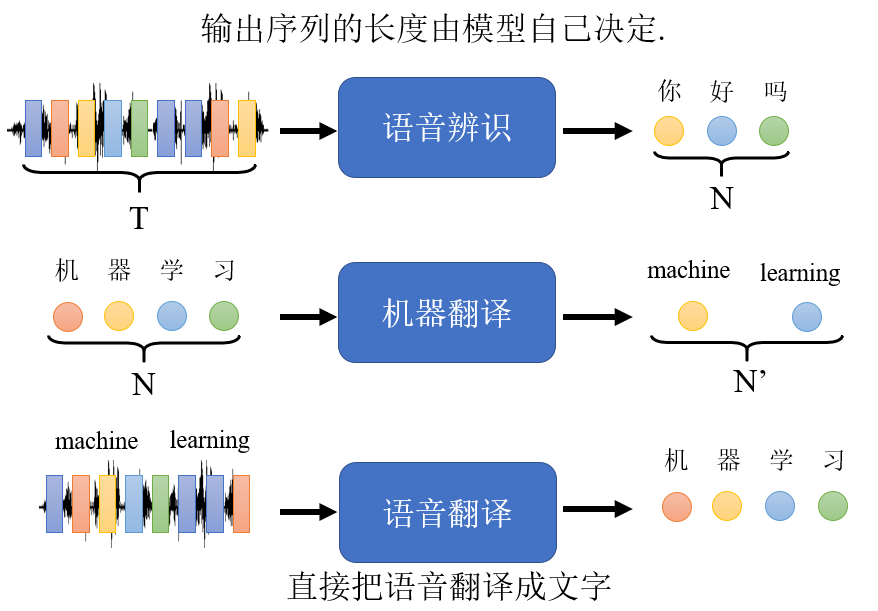
之前讲的self-attention模型中,输入和输出数量相等。现在我们来看,当输出序列的长度不确定时,该怎么办?这种情况只能让模型来自己来决定输出长度。
如下图所示,举个输出序列长度不确定的例子,如语音辨识、机器翻译、语音翻译等。
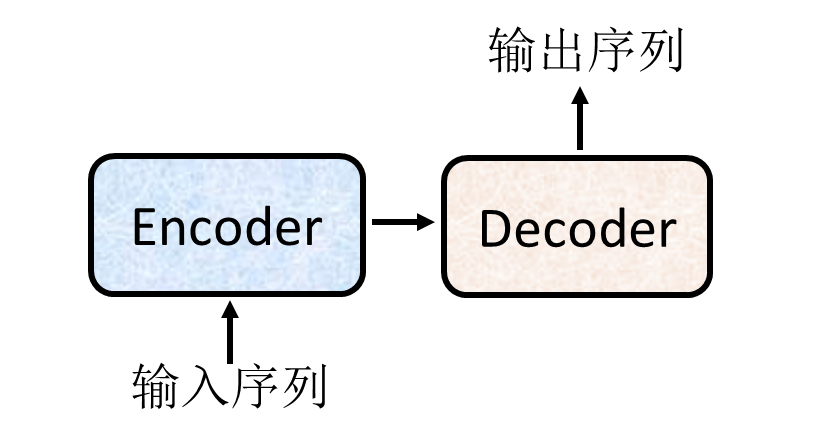
Transformers是一个标准的Seq2Seq, 包含Encoder(编码器)和Decoder(译码器)两部分。
Transformers的网络结构
整体结构
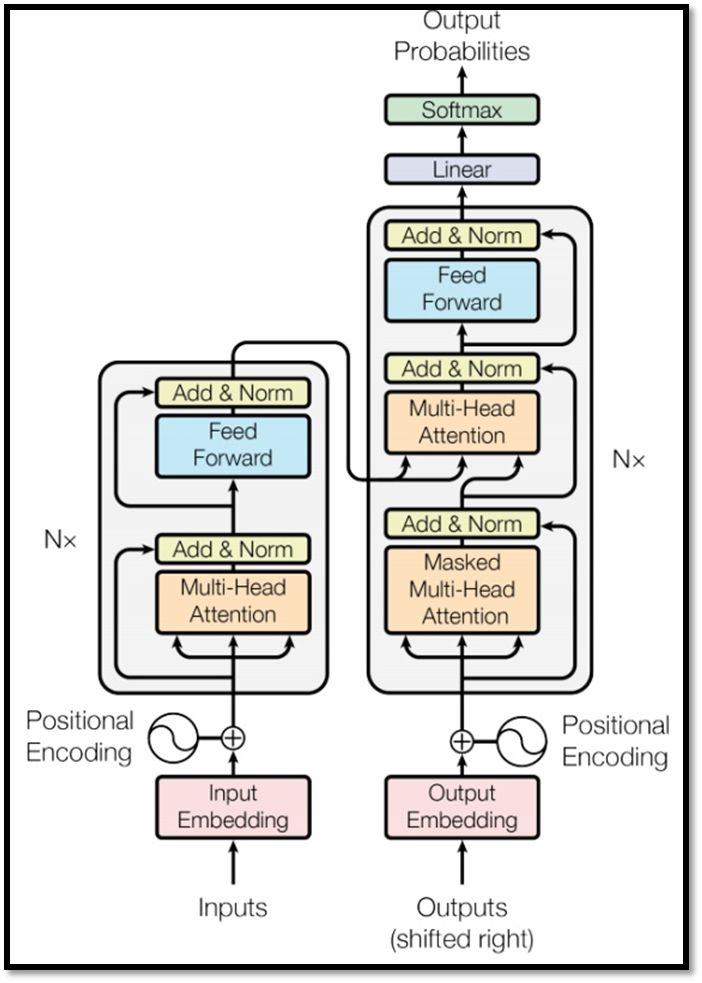
Transformers由Encoder和decoder组成,并且Encoder和decoder都包含6个block。如下图所示,其中N_x=6。
Encoder结构
如下图所示,为Transformers的Encoder部分。每一个Encoder Block的结构如右图所示。
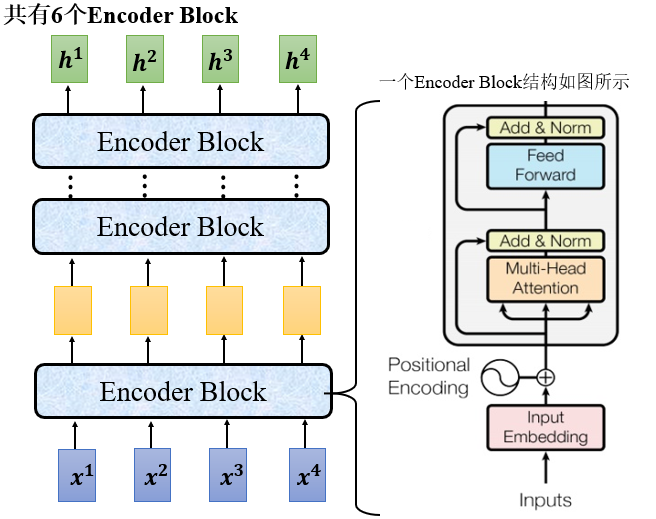
打开来看Encoder block, 如下图所示。对于Encoder而言,输入是inputs x经过编码之后,再加上位置编码p(Positional Encoding),得到一个结果,再传入Multi-Head Attention,得到输出结果。得到的输出结果和输入相加(这个过程称之为残差,Risidual),然后经过Layer Norm,传入全神经网络,全神经网络的输入结果和输入相加,再经过Norm,得到最终输出结果。
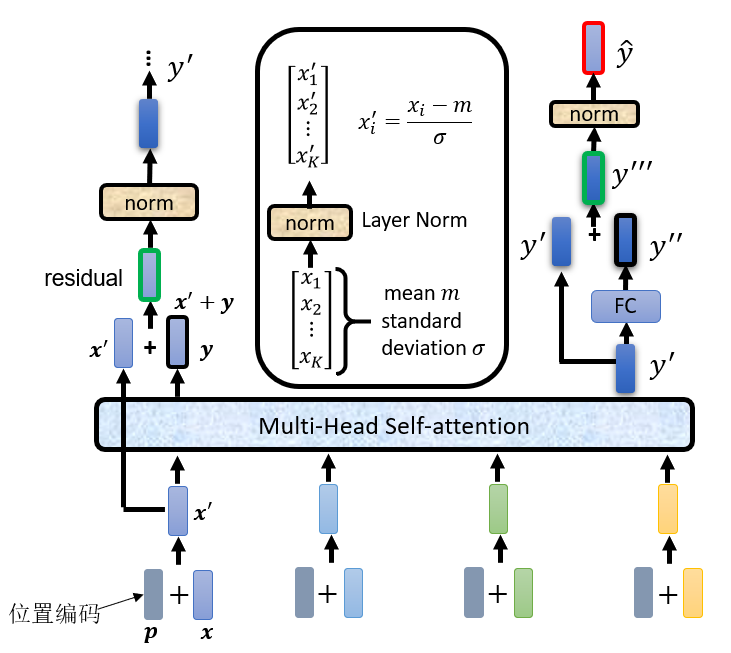
上面的过程重复6次,完成编码过程。
这里有两个疑问,在问题答疑里面讲解,分别是为什么要做residual 和 为什么要做Layer Norm。
Decoder结构
如下图所示,Encoder的输出结果作为Decoder的输入来获得预测结果,下面会讲Encoder的输入在decoder中具体是怎么处理的。
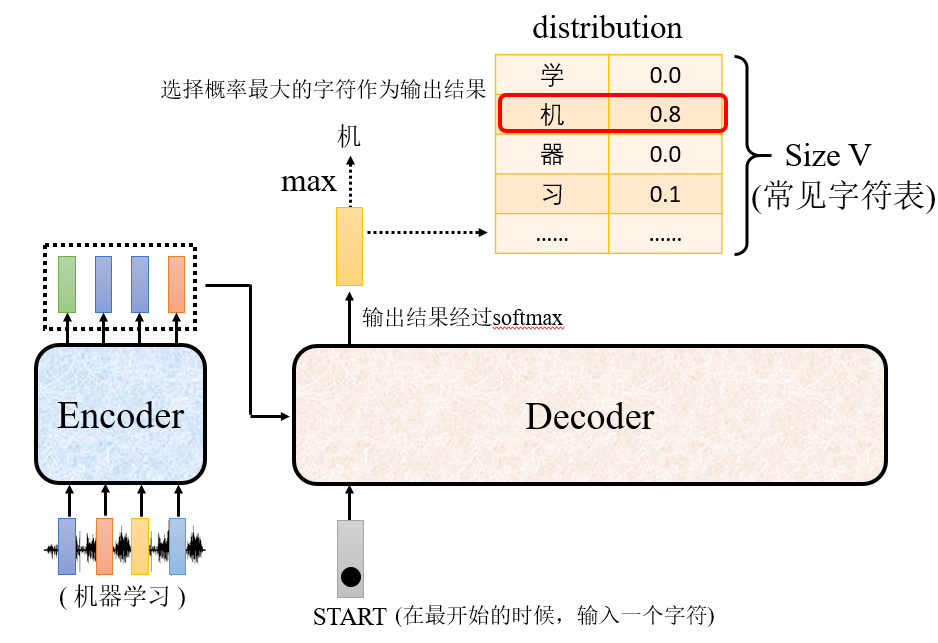
- 输入
特殊字符作为开始,经过Decoder,得到输出结果,输出结果是每一个字符的概率,选择概率最大的那个字符作为输出结果。比如说,让机器翻译一段内容为“机器学习”的语音,期望decoder的输出的第一个字符是“机”。
- 把上个时刻的输出作为当前时刻的输入,经过decoder,得到输出。比如说输入“STASRT, 机”,得到“器”的输出。
- 以此类推,直接输出“END”字符,意味着结束。
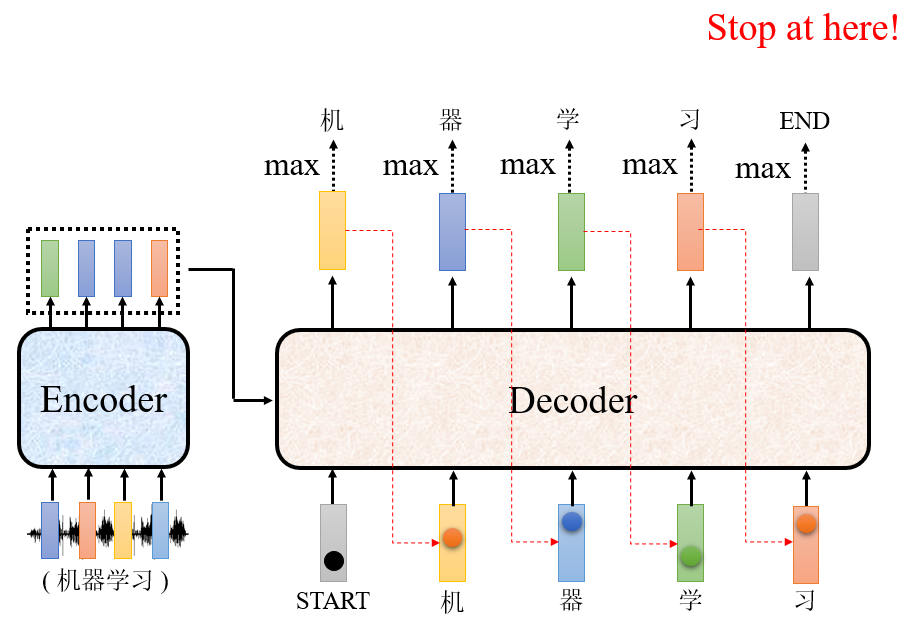
上述是Decoder的大致运作流程。具体内容是怎么运作的呢?
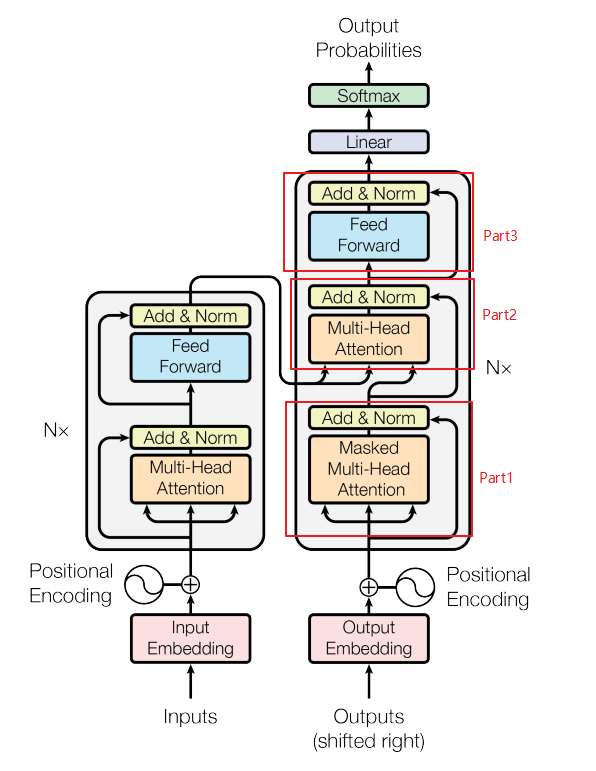
如下图所示,decoder的内部结构分为三部分
Part1 Masked Multi-Head Attention
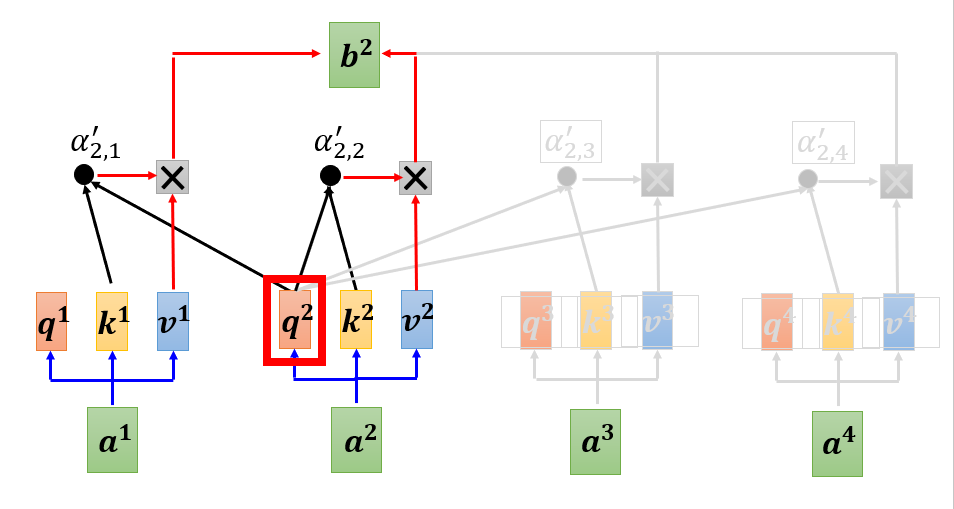
在decoder部分,对输入矩阵进行的masked multi-head attention操作,这是因为decoder是一个字符一个字符的进行输出,比如说输出“机器学习”,是先输出“机”,再输出“器”,再输出“学”,再输出“习”。也就是说,decoder只能看到当前时刻及以前时刻的信息,无法看到未来的信息,因为,decoder在对输入进行处理时,需要对未来时刻的信息进行遮掩。
如下图所示, 输出b^2是根据a^1和a^2预测得到的,而与a^3和a^4无关。
再经过add & LayerNorm,输出。
Part2 Multi-Head Attention
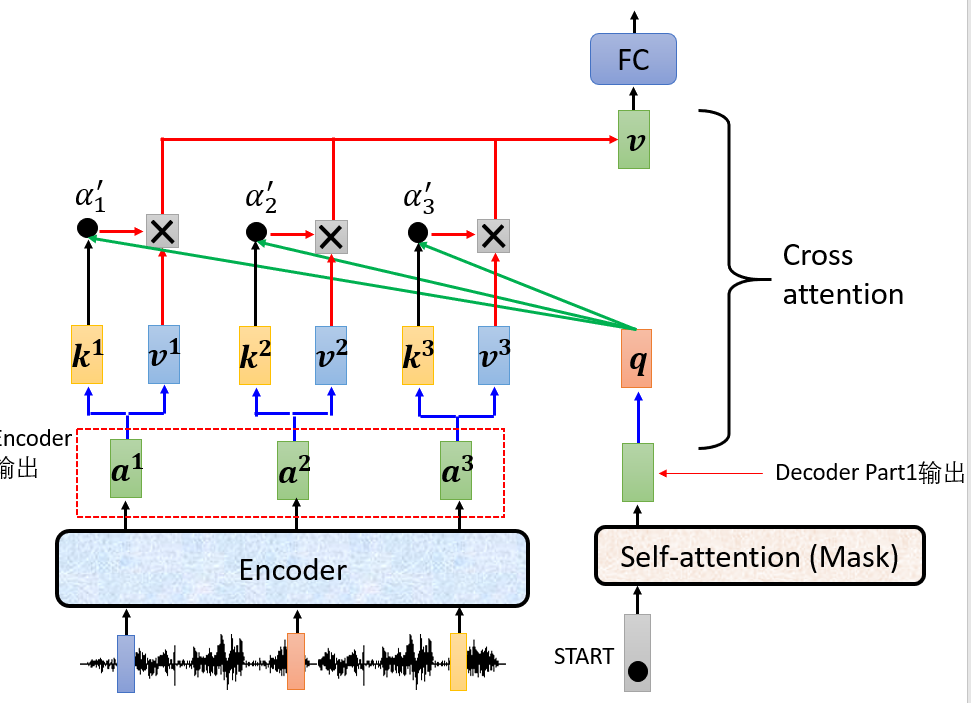
在第二部分,就需要将encoder的输出结果和刚才decoder Part1的输出结果进行联合处理了。将Encoder的输出输出,和decoder Part1 部分的输出做Cross attention, Cross attention的运作流程还是和self-attention一样,只不过是输入序列是由两个不同的序列组成。
Part3 LinearLayer 和 SoftmaxLayer
Part 3就是常见的处理了,经过Linear层和Softmax,选择概率最大的结果作为输出。